Neural Network Representation
이제부터 다룰 neural network의 기본적인 구조는 다음과 같다..
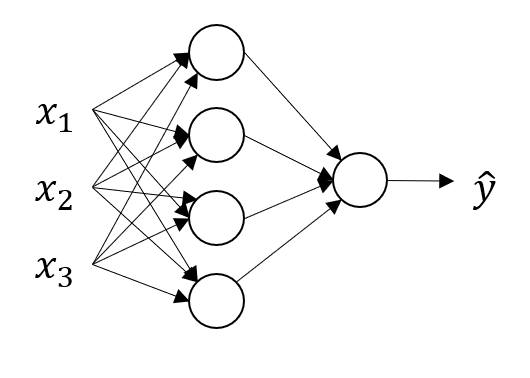
다음의 그림에서 각 열을 레이어라고 부르며 구체적으로,
- : input layer
- 중간 레이어 : hidden layer, 각각은 hidden unit에 해당.
- : output layer
라고 부른다. 또한 위의 그림과 같은 경우를 2 layer neural network라고 부르는데, 일반적으로 input layer는 layer의 수에 포함시키지 않기 때문이다.
neural network는 그림에서 직관적으로 파악할 수 있듯, 화살표가 가리키는 방향으로 값을 전달한다. 따라서 input layer에서는 을 hidden layer의 입력값으로 전달한다. 다음으로 이를 전달받아 hidden layer에서 어떠한 함수를 통해 최종적으로 값을 산출하며, 이 값을 로 표기한다. 는 다시 output layer의 입력값이 되며, output layer에서 또다른 함수를 통해 최종적으로 를 산출한다.
또한 hidden layer는 두 개의 파라미터를 가지는데, 가중치 행렬인 과 bias 이 있다. 후술하겠지만, 위의 예제에서 가중치 행렬은 (4, 3), bias는 (4, 1) 벡터가 된다.
정리하자면 neural network는 input, hidden, output의 세 종류의 layer로 구분될 수 있으며, 각각의 레이어에서 사용되는 표기법은 다음과 같은 것들이 있다.
| input layer | hidden layer | output layer | |
|---|---|---|---|
| output value | |||
| parameters | weight 과 bias | weight 과 bias | |
| dimensions | 는 (4, 3), 는 (4, 1) | 는 (1, 4), 는 (1, 1) |
Computing a Neural Network's output
이제 하나의 unit 별로 어떠한 연산이 이루어지는지를 알아보자! 다음의 예시는 hidden layer에 하나의 unit만이 존재하는 경우 어떻게 결과값을 산출하는지를 나타내는 그래프이다.
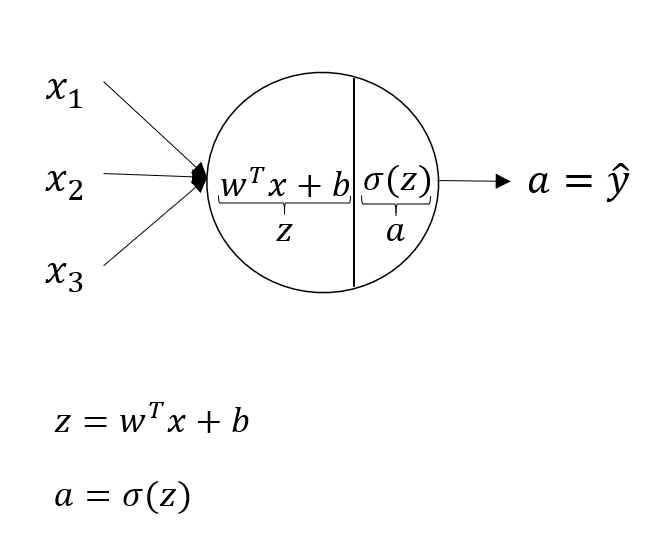
입력값 는 를 거쳐 최종적으로 를 산출한다.
위에서 살펴본 2 layer neural network의 hidden layer의 경우 이를 여러 unit으로 확장한 것에 불과하므로, 다음과 같은 식을 통해 와 를 산출한다.
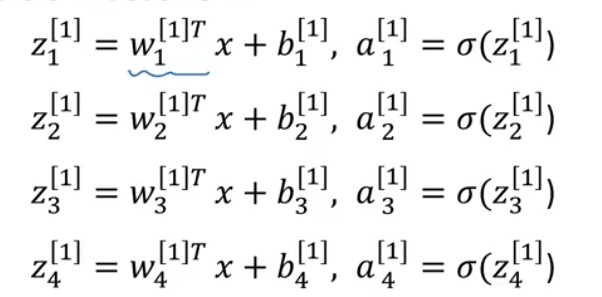
실제 신경망 구현에서는 위의 연산을 반복문을 통해 구현하지 않고, 행렬로 표현하여 다음과 같이 계산한다.
Vectorizing across multiple examples
i개의 training data가 있을 때의 학습은 다음과 같이 이루어진다.
실제로 구현할 때에는 반복문을 사용하지 않고 다음과 같이 각 training data를 열벡터로 두는 행렬을 만들어 계산하게 된다.
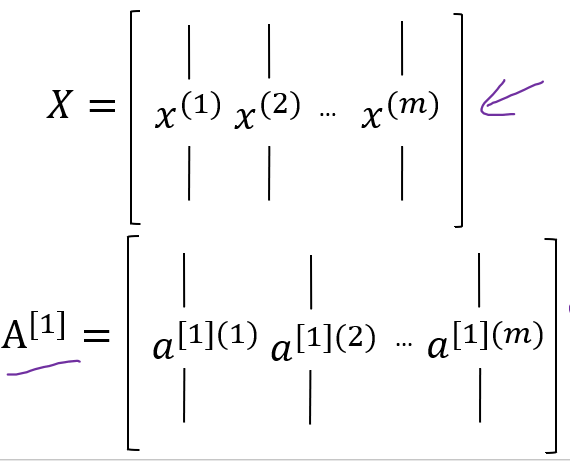
Activation function
지금까지 다루어왔던 예제에서 회귀를 통해 예측된 는 activation function(활성함수)을 통해 변환된다. 이전의 강의에서는 이 activation function으로 시그모이드 함수를 사용해 왔다. 이번 강의에서는 여러 activation function을 소개하고 있다.
- tanh
- -1과 +1 사이의 값을 가짐
-
데이터를 centering하는 역할을 수행함으로써 데이터들의 평균이 0에 근접하도록 한다. 이 경우 다음 레이어에서의 학습이 보다 수월하게 이루어질 수 있다.
-
RELU
- z값이 너무 크거나 너무 작으면 시그모이드와 tanh의 값이 1과 -1에 가까워질 수 있다. 즉 기울기가 0에 가까워지며, gradient descent가 느려질 수 있다. 이 단점을 보완하는 활성함수
- z과 0보다 작으면 0으로 만들지만, 그렇지 않으면 계속 증가함( = )
-
기울기가 0에 가까워지지 않고 z에 따라 달라지기 때문에, tanh에 비해 학습이 빠르다.
-
Leaky ReLU
- 가 양수인 경우에는 ReLU와 동일하지만
- 인 경우
강의에서는 결과값이 binary classification인 경우에는 시그모이드 함수를 사용하고, 다른 경우에는 ReLU나 tanh를 사용하라고 권유한다.
| 수식 | 특징 | |
|---|---|---|
| sigmoid | 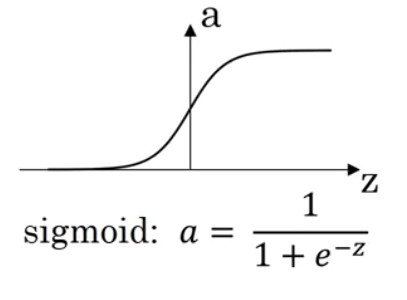 |
* 데이터가 사이의 값을 가짐 * binary classification시 사용 |
| tanh | 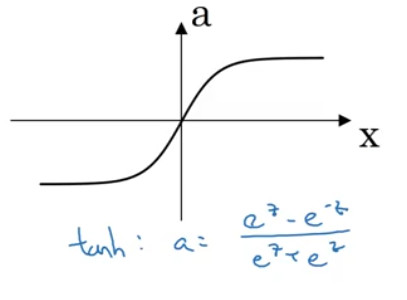 |
* 데이터가 사이의 값을 가짐 *데이터의 평균이 0이 되도록 centering |
| ReLU | 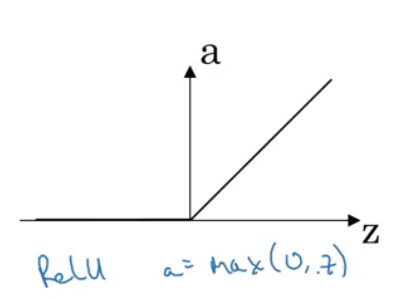 |
* sigmoid와 tanh에 비해 학습이 빠름 |
| leaky ReLU | 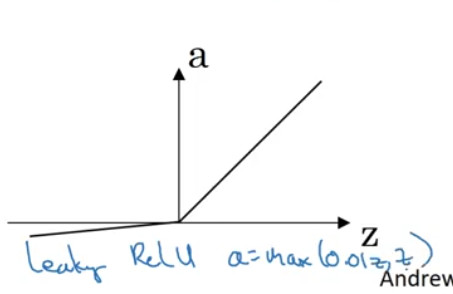 |
* ReLU와 유사! |
Why do you need non-linear activation functions?
활성함수에는 선형 활성함수와 비선형 활성함수가 존재한다. 비선형 활성함수에는 위에서 다룬 sigmoid, ReLU 등이 있으며, 선형 활성함수는 다음과 같이 정의된다. 즉 input과 output이 동일한 함수를 선형 활성함수라고 하는데, 둘이 동일하기 때문에 이를 identity function이라고 부른다.
hidden layer에서는 선형 활성함수를 사용해서는 안된다. 간단한 예시를 통해 직관적으로 이해할 수 있다. 만약 각 unit의 활성함수가 선형이라고 하면 다음과 같이 계산될 것이다.
a[1] = w[1] * x[0] + b[1]
a[2] = w[2] * a[1] + b[2] = w[2] * ( w[1] * x[0] + b[1] ) + b[2]
a[3] = w[3] * a[2] + b[3] = ...
이므로 각각의 레이어를 합쳐서 하나의 선형 함수로 표현할 수 있다. 즉 레이어를 쌓는 의미가 없어지기 때문에, 활성함수는 비선형적이어야 한다.
Derivatives of activation functions
역전파 알고리즘을 이용할 때에는 각 활성 함수의 기울기를 구해야 한다. 강의에서는 미분에 대한 자세한 설명은 생략하고, 각각의 도함수가 어떻게 계산될 수 있는지만 설명하고 있기 때문에 이를 표로 정리해보았다.
| 수식 | 특징 | 도함수 | |
|---|---|---|---|
| sigmoid | |
* 데이터가 사이의 값을 가짐 * binary classification시 사용 |
|
| tanh | |
* 데이터가 사이의 값을 가짐 *데이터의 평균이 0이 되도록 centering |
|
| ReLU | |
* sigmoid와 tanh에 비해 학습이 빠름 | |
| leaky ReLU | |
* ReLU와 유사! |
Gradient descent for Neural Networks
아래의 이미지처럼 로지스틱 회귀의 값을 구했다고 가정하자.
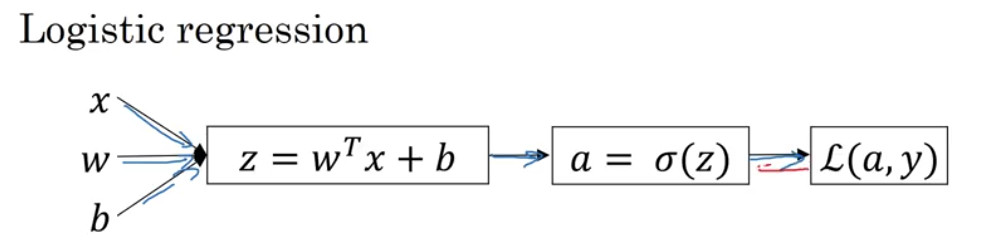
다음으로 해야할 일은 gradient descent를 이용하여 parameter인 W와 b를 업데이트하는 것이다. 업데이트는 다음을 반복함으로써 이루어진다.
위에서 a와 z에 대한 도함수를 계산하는 공식이 주어졌기 때문에 실제로 구현할 때에는 이를 식에 대입하기만 하면 된다! 신경망이 확장되더라도 이러한 계산을 반복하기만 하면 된다.
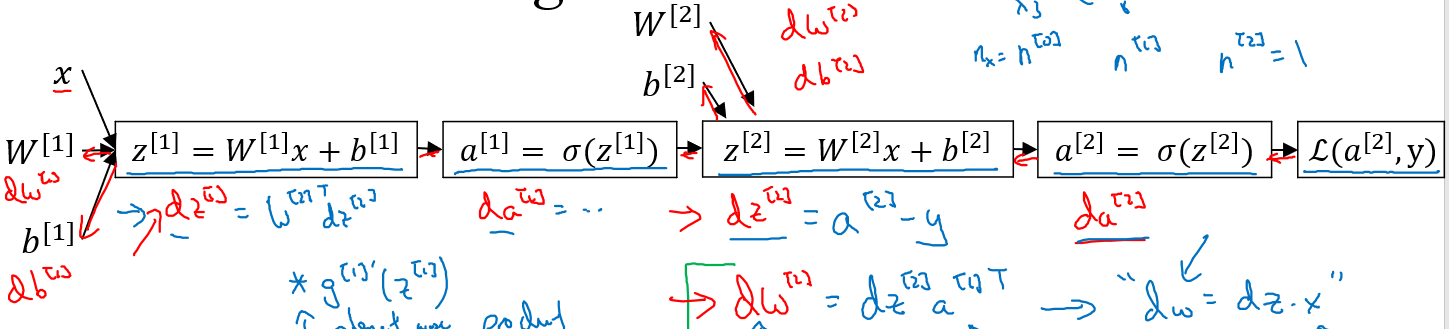
그리고 다음의 강의노트는 이를 실제로 구현할 때 어떻게 구현해야하는지를 설명하고 있다(구현할 때 참고하면 되는 내용같아서 따로 설명하지는 않을게요)
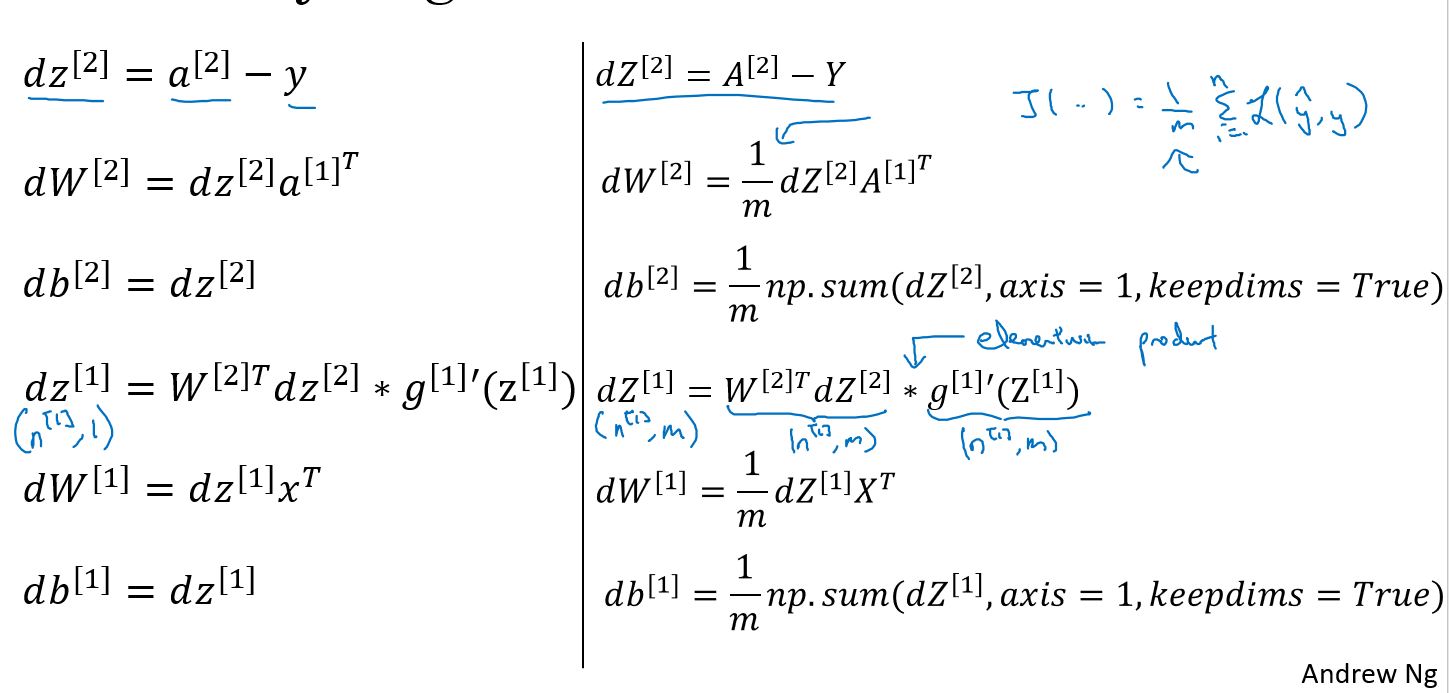
Random Initialization
드디어! shallow neural network의 마지막 강의이다!ㅠㅠ 이번에는 앞서 이용했던 W와 b를 학습할 때 가장 먼저 어떤 값으로 초기화해야 하는가에 대해 논한다. 가장 간단한 초기화 값은 모든 값을 0으로 두는 것이다. 하지만 이 경우 gradient descent를 이용한 학습이 불가능하다.
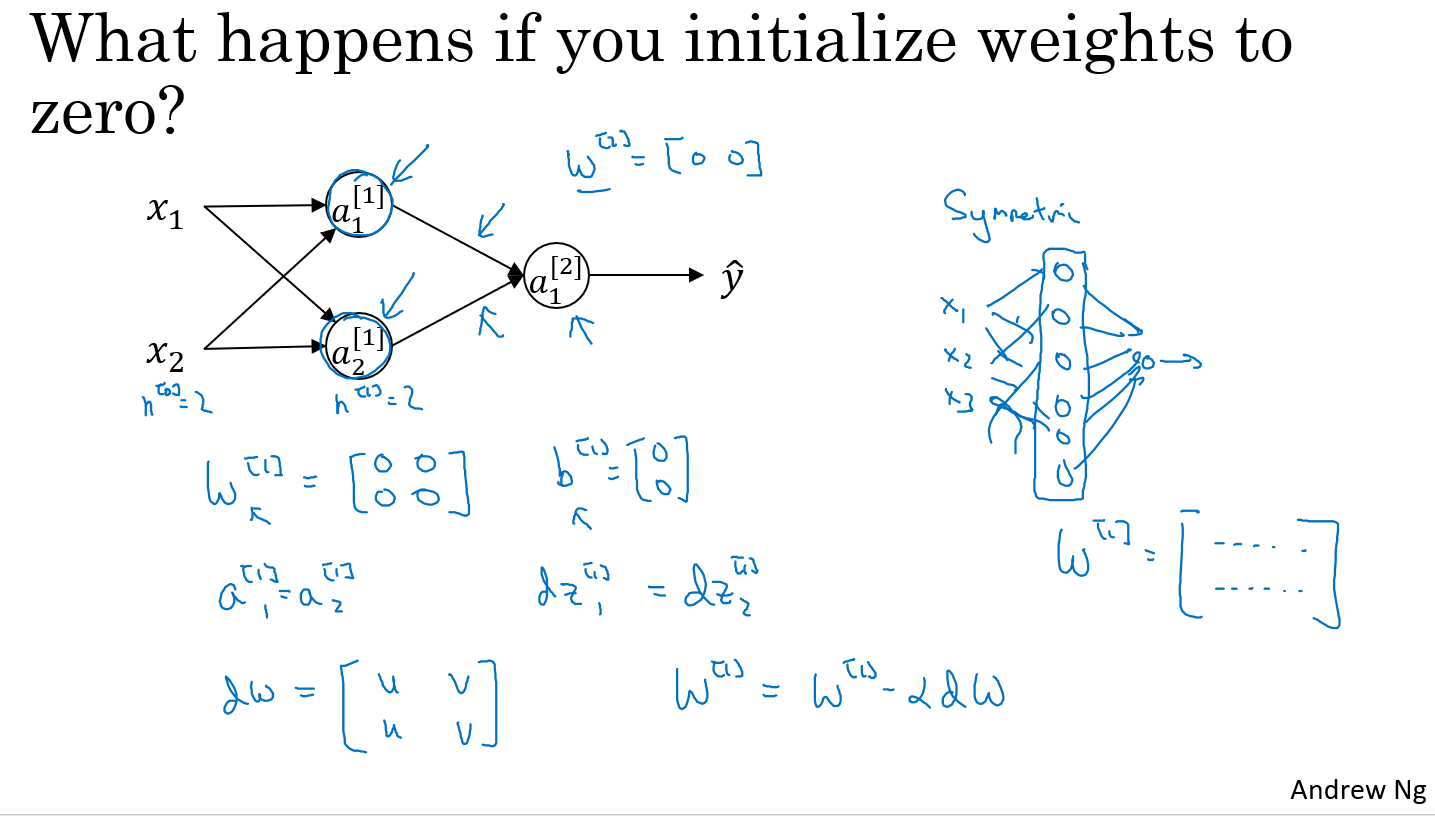
위의 예제는 가중치를 0으로 두었을 때 어떤 결과가 나타나는지를 보여준다. 가중치와 bias가 0인 경우 모든 unit이 동일한 값을 산출하기 때문에, 하나의 unit을 두는 것과 다를바 없는 결과를 낳게 된다. 따라서 가중치를 초기화할 때에는 임의의 값으로 초기화하는 것이 좋은데, 강의에서는 아래의 연산을 통해 가중치를 초기화할 것을 권장한다.
W_1 = np.random.randn(dim) * 0.01
b_2 = np.zeros(dim)
가중치에 0.01을 곱하는 이유는 tanh나 시그모이드 함수가 output layer의 활성함수인 경우, z값이 너무 크거나 너무 작은 경우 해당 지점에서의 기울기가 아주 작은 값을 가져 학습이 느려지기 때문이다. 한편 b에 대해서는 앞서 설명한 문제가 발생하지 않기 때문에 0으로 초기화해도 문제가 발생하지 않는다.